
Bereits seit über 20 Jahren, also seit die ersten Programme, die das Leben von Übersetzern leichter und das der Kunden angenehmer machen - so genannte Translation Memories (abgekürzt „TM“) - auf den Markt kamen, arbeiten auch wir mit diesen Programmen. Worum handelt es sich dabei? Wenn ich von »Hartmann Fachübersetzungen« erzähle und was ich seit fast 40 Jahren beruflich mache, höre ich oft die mehr oder weniger rhetorisch gestellte Frage: ‚Ach, da arbeitet ihr wohl auch mit „solchen“ Programmen?‘ - mit der unterschwelligen Vermutung: ‚Da braucht ihr wohl gar nichts mehr selber zu machen, und der Computer macht alles für euch?!‘ Tja, wenn das so einfach wäre...! Leider - oder: Gott sei Dank - ist das nicht so.
Die Bezeichnungen, die das computergestützte Übersetzen von Texten umschreiben, sind vielfältig und unterschiedlich - eine geht bereits aus der eben genannten deutschen Übersetzung hervor: CAT-Tools, also Werkzeuge / Hilfsmittel zur computerunterstützen (engl. „computer-aided“) Übersetzung. Das ist der allgemeine Oberbegriff für alles, was dem Übersetzer beim Übersetzen hilft - wohlgemerkt: hilft, also nicht die komplette Arbeit abnimmt, und das wird leider oft von Außenstehenden - also allen, die sich nicht professionell mit Übersetzungen beschäftigen - durcheinander gebracht. Die Haupt(kopf)arbeit macht nach wie vor der Übersetzer selbst. Die hier erwähnten Translation Memories sind lediglich ein Speicher aller Übersetzungen, die der Übersetzer, der das Translation Memory (mit seinen selbst erstellten Übersetzungen) „füllt“ und verwaltet, im Laufe der Jahre angefertigt hat.
Das Übersetzungsbüro Hartmann bzw. (seit der Umfirmierung 2022) »Hartmann Fachübersetzungen« gibt es bereits seit etwas über 32 Jahren, und wir arbeiten seit etwas über 20 Jahren mit Translation Memories - da können Sie sich vorstellen, wie viele Übersetzungen in diesem bzw. (wir arbeiten ja mit mehreren Translation Memories) diesen TMs im Laufe der Jahre bereits gespeichert sind. Ein wahrer Schatz, auf den wir jederzeit immer wieder zugreifen können, um Textpassagen, die sich in vielen Betriebsanleitungen, Vertragstexten oder Handelsregisterauszügen wiederholen, „hervorzuholen“, um sie für unsere Übersetzungen zu nutzen. Profitieren auch Sie also von den Vorteilen, die die Arbeit mit einem Translation Memory mit sich bringt!

Zunächst wird der dem Übersetzungsbüro vom Kunden gelieferte
englische, deutsche polnische etc. Ausgangstext in das
Translation Memory eingelesen. Dabei wird der Text in bestimmte
Einheiten - Segmente genannt - zerlegt. Man sagt dazu auch,
dass der Ausgangstext in das Translation Memory importiert
wird. Die Ausgangsstruktur des Textes wird dabei
beibehalten.
Dies hat für den Übersetzer mehrere Vorteile: Ein nicht zu
unterschätzender Vorteil ist, dass der Übersetzer nicht durch
in das Dokument eingebettete Grafiken oder „abgelenkt“ wird.
Zum einen kann er sich dadurch voll auf den zu übersetzenden
Text konzentrieren, zum anderen „setzt“ das jeweilige
Translation Memory den (dann übersetzten) Text nach Abschluss
der Übersetzung und dem so genannten Export wieder in das
ursprüngliche Format um, und der Übersetzer braucht „bloß“ noch
einmal die Formatierung zu kontrollieren - aber das tut er ja
ohnehin, wenn er den Text generell nochmals liest und auf
Richtigkeit der Übersetzung kontrolliert. Mit anderen Worten:
Der Übersetzer muss nicht während der Übersetzung z.B.
Textboxen erweitern, damit der zu übersetzende Text sichtbar
wird oder Formatierungen an Tabellen ändern, und ist somit
nicht durch Nebenarbeiten belastet.
Wie der für den Zweck der Übersetzung mit einem Translation Memory segmentierte Text dann aussieht, sehen Sie hier an zwei Beispielen mit (einer etwas älteren Version von) TRANSIT und mit memoQ!
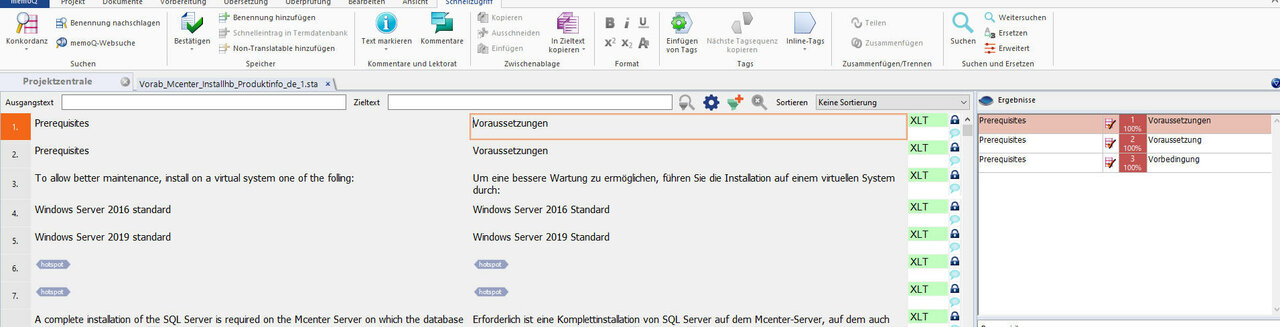
Ein weiterer Vorteil dieses Imports des Ausgangsformats des zu
übersetzenden Textes ist, dass der Übersetzer auch Texte in
Formaten bzw. aus Programmen bearbeiten kann, die er selbst
nicht hat. Beispiel: Der Kunde schickt eine Datei in InDesign.
InDesign ist sehr teuer - früher: bis vor ca. 10 Jahren -
musste man es noch für eine mittlere vierstellige Summe kaufen,
heute muss man es im Rahmen eines monatlichen Abos bezahlen.
Das kann und will sich nicht jeder Übersetzer leisten.
Der Vorteil des Translation Memorys ist, dass der Übersetzer
die - um bei dem Beispiel zu bleiben - InDesign-Datei trotzdem
in sein Translation Memory einlesen, den Text übersetzen und
somit den Auftrag annehmen und zur Zufriedenheit seines Kunden
erledigen kann, obwohl er das Programm InDesign selbst nicht
hat bzw. keine Abo-Gebühr dafür bezahlt.
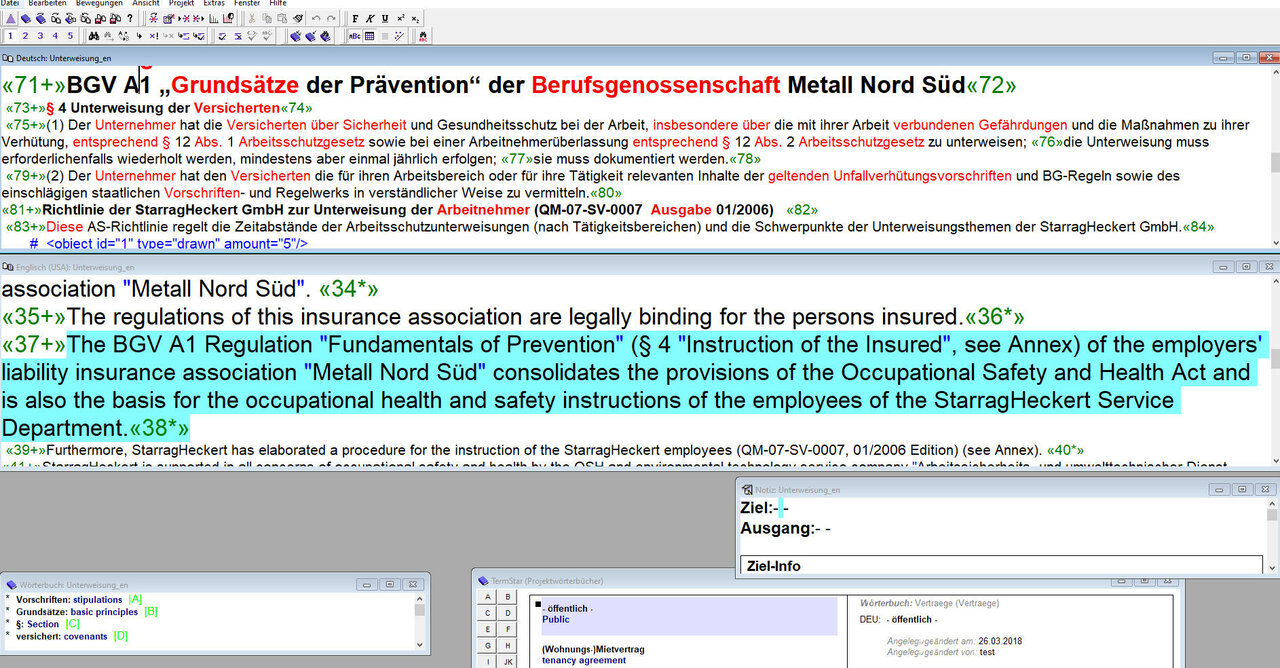
Dieser Einwand ist berechtigt! Zwar ist die Segmentierung des zu übersetzenden Ausgangstextes - wie oben dargelegt - ein enormer Vorteil für den Übersetzer, aber der Übersetzer sieht nicht mehr, ob das, was er gerade übersetzt, eine Überschrift ist oder lediglich eine Aufzählung innerhalb des Fließtextes oder eine Tabelle bzw. sieht er auch oft nicht, welcher Satz eigentlich wohin gehört, da manche Translation Memories den Text hin und wieder so segmentieren, dass teilweise auch Sätze getrennt werden und beispielsweise ein Teil des Satzes manchmal an vorderer Stelle im segmentierten Text des Translation Memorys stehen und der Rest des Satzes erst eher am Ende. Das sind zwar eher Ausnahmen, aber es kommt vor.
In der Regel - zumindest machen das unsere Kunden SIEMENS und
ENREGIS so, aber auch viele andere, die ihre Übersetzungstexte
in speziellen Formaten liefern - geben uns die Kunden
zeitgleich mit dem Übersetzungsauftrag auch eine PDF mit dazu.
Diese sollte der qualitätsbewusste Übersetzer zusammen mit dem
im Translation Memory importierten Text ebenfalls mit öffnen.
Seit einiger Zeit erscheint bei den regelmäßig erscheinenden
Versionen des Translation Memorys memoQ zum Beispiel regelmäßig
beim Starten von memoQ ein Fenster, das die Suche nach der
entsprechenden PDF mit dem zu übersetzenden Ausgangstext
anbietet. Bestimmte Kunden, wie z.B. SIEMENS, kontrollieren
sehr genau, ob der Übersetzer das auch gemacht hat, denn man
merkt bei der Kontrolle des übersetzenden Textes sehr genau, ob
der Übersetzer auch mal einen Blick in die PDF „riskiert“ hat
oder nur stur „drauflos“ übersetzt hat, ohne auf den Kontext zu
achten.
Einfaches Beispiel: Im Ausgangstext steht sinngemäß: ‚Das sehen
Sie in der Abbildung unten‘ - „unten“ ist aber zum
Beispiel ein Diagramm mit einer Kennlinie des Spannungsverlaufs
in Abhängigkeit von der Zeit zu sehen, und der Übersetzer
schreibt - bei der Übersetzung ins Englische „For details,
refer to the illustration below“ oder etwas in der Art
wäre das zum Beispiel nicht ganz korrekt - „diagram“ o.dgl.
wäre besser gewesen. Dazu muss er aber wirklich die PDF mit dem
Ausgangstext bei der Hand haben bzw. parallel zum mit dem
Translation Memory segmentierten Text geöffnet haben, damit er
den Text adäquat übersetzen kann.
Klares NEIN! Außer den oben genannten Vorteilen (Bearbeitung von Texten aus Programmen, die der Übersetzer nicht hat und somit nicht zu kaufen braucht, Auflösung der Formatierung und Layoutierung zum Zweck der komfortableren Übersetzung etc.) profitieren auch unsere Kunden davon, dass »Hartmann Fachübersetzungen« seit ca. 25 Jahren mit Translation Memories arbeitet.
Ein wesentlicher Vorteil ist die Nutzung von bereits vorhandenen Übersetzungen. „Das Leben ist so langweilig - alles ist schon mal gesagt worden!“, sagte der alte Mann... Naja, das ist sicher übertrieben, aber irgendwie ist da doch was Wahres dran! Erinnern wir uns doch nur einmal an bestimmte Sätze oder Formulierungen, die schon aufgrund eines bestimmten Kontextes oder einer bestimmten Situation immer wiederkommen und immer wieder in derselben Situation oder im selben Kontext gesagt bzw. geschrieben werden. Das sind solche Sätze, wie „Weitere Informationen dazu finden Sie in ...“ in der schriftlichen Kommunikation oder die Reaktion auf „Vielen Dank“ - „Bitte, gern geschehen!“. Das sind zwar sehr einfache Bespiele, und insbesondere das zweite ist nicht unbedingt einer technischen Übersetzung entnommen, aber es wird ersichtlich, dass es viele Sätze oder Wortgruppen gibt, die man zu den Standardformulierungen zählen kann und immer so und nicht anders im Sprachgebrauch vorkommen - und das gilt auch für die Fremdsprache. Schon allein deshalb sollten bzw. können diese Formulierungen auch in der Fremdsprache bzw. der Sprache, in die der Text übersetzt wird (bei Übersetzungen ins Deutsche), auch immer gleichlautend wiedergegeben werden. Und genau solche immer wiederkehrenden Standardformulierungen macht sich ein Translation Memory zunutze; diese werden - sofern man einen Text in ein Translation Memory zur Bearbeitung eingelesen und damit übersetzt hat - gespeichert und stehen dem Übersetzer somit zur Verfügung, sodass er den entsprechenden Satz oder die entsprechende Wortgruppe nicht mehr nachzuschlagen oder nicht mehr zu überlegen braucht, wie er das übersetzt - was ihm letztendlich Zeit und Arbeitsaufwand erspart, wovon wiederum der Kunde profitiert, was sich für ihn in barer Münze auszahlt.

Aber Translation Memories haben nicht nur bei den oben erwähnten Standardformulierungen Vorteile. Der wesentliche und für den Kunden offensichtliche Vorteil, der auch in der Praxis von »Hartmann Fachübersetzungen« sehr oft vorkam und vorkommt, sind so genannte Differenzübersetzungen. Was versteht man darunter? Angenommen, eine Firma, die im Jahre 2012 ein Programm zur Produktionssteuerung entwickelt hat, macht ein oder mehrere Software-Updates, entwickelt vielleicht noch ein paar neue Features, und stellt 2023 fest, dass die von uns 2012 ins Englische übersetzte Programmbeschreibung einschließlich aller Screenshots, Softwaretexte usw. nicht mehr aktuell ist. Die Firma beauftragt uns also mit der Übersetzung der neuen Softwarebeschreibung, Stand 2023. Da ja nun aber nicht alles in dem neuen Handbuch von 2023 neu ist, möchte die Softwarefirma - verständlicherweise - nicht alles nochmal komplett neu bezahlen. Das muss sie auch nicht!
Und hier kommen die Translation Memories ins Spiel: Um bei dem Beispiel oben zu bleiben - wir haben die Softwarebeschreibung damals im Jahre 2012 mit einem Translation Memory übersetzt. Dadurch sind die „alten“ Übersetzungen von damals darin gespeichert. Wenn nun die neue Fassung des Handbuchs wieder in das Translation Memory eingelesen wird, erkennt das TM alles, was damals (2012) bereits übersetzt wurde, übernimmt diese Passagen als „übersetzt“ bzw. „vorübersetzt“ (das ist der Zustand, mit dem die Segmente in einem Translation Memory nach Import des neuen, aktuellen Textes gekennzeichnet werden), und diese übersetzten bzw. vorübersetzten Segmente werden dem Kunden dann nicht mehr ein weiteres mal oder nur noch zu einem sehr geringen Prozentsatz in Rechnung gestellt. Dieser „geringe Prozentsatz“ beträgt in der Regel 20 ... 25 % des vollen Preises für die jeweilige Zeile und spiegelt den Aufwand wider, den der Übersetzer, der mit dem Translation Memory arbeitet, trotzdem noch hat, um die als übersetzt oder vorübersetzt gekennzeichneten Segmente zu kontrollieren und ggf. anzupassen. So kann es ja passieren, dass zu der 2012 erstellten Softwarebeschreibung Sätze dazugefügt worden sind, die dann nach Aktualisierung des Handbuchs im Jahr 2023 nicht mehr zu der alten Übersetzung passen. Das prüfen die Übersetzer von »Hartmann Fachübersetzungen« sorgsam und passen die alten Segmente entsprechend an, und die ca. 20 % des ursprünglichen Zeilenpreises für die Überprüfung und Anpassung spiegeln diesen Aufwand wider.
Auf jeden Fall bieten Translation Memories dem Kunden hohe Terminologiesicherheit! Bei TRANSIT zum Beispiel sind alle vom Übersetzer in die Datenbank aufgenommenen Termini rot gekennzeichnet, und der Übersetzer kann den entsprechenden Eintrag mit einer speziellen Tastenkombination in die Übersetzung übernehmen. Oft besteht die Möglichkeit, ergänzend zu dem jeweiligen Glossareintrag noch weitere Informationen einzugeben, wie z.B. die Quelle - d.h. ob der Übersetzer das jeweilige Übersetzungsäquivalent im Internet gefunden hat, im zweisprachigen Prospekt eines Herstellers oder ob die jeweilige Fachwortübersetzung ihm in Form eines vom Kunden gelieferten Glossars zur Verfügung gestellt worden ist.

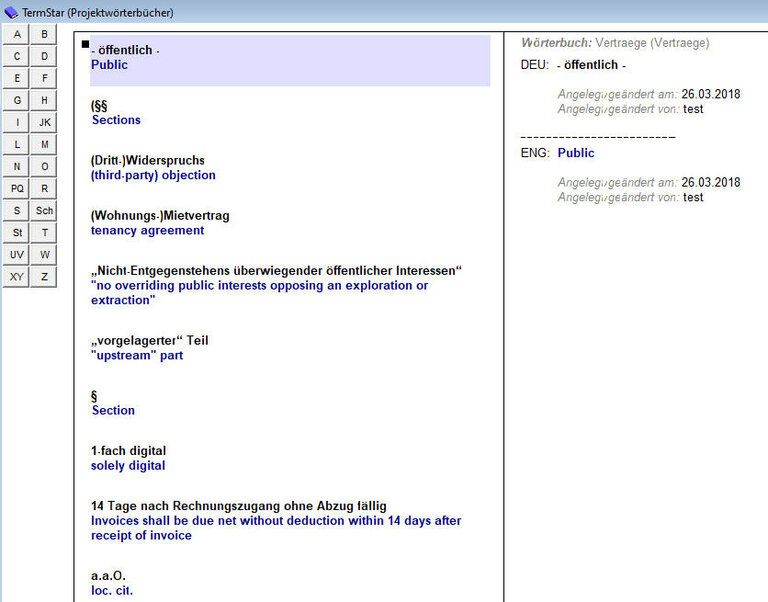
Die Einträge für das jeweilige Fachwortglossar tragen wir
entweder während der Übersetzung ein oder in der Phase der
Nachbereitung.
Nachbereitung? Ja - es kommen ja manchmal Anmerkungen vom
Kunden in Form eines Feedbacks zu uns zurück, dass er zum
Beispiel bestimmte Fachwörter bevorzugt. Das heißt in solch
einem Falle nicht, dass die von uns verwendeten Fachbegriffe
falsch waren, aber manchmal bevorzugt der Kunde eben bestimmte
Fachbegriffe, weil die eben schon „seit Jahren so verwendet“
werden, weil sich seine Kunden daran gewöhnt haben oder weil
der Fachbegriff eben „einfach besser“ ist. In solchen Fällen
gehen wir die bereits zum Kunden gelieferte Übersetzung noch
einmal durch und prüfen nochmals alle Fachausdrücke genau,
bereinigen und korrigieren ggf. bestimmte Glossareinträge,
damit der Kunde bei der nächsten Übersetzung die Fachausdrücke
in seiner Übersetzung wiederfindet, die er dort sehen will. So
merkt er auch, dass wir die Übersetzung nicht nur vor der
Auslieferung gründlich prüfen, sondern auch danach.
Wir lassen den Kunden also niemals allein und betreuen ihn auch
nach Lieferung der Übersetzung. Wir setzen auf
langfristige Zusammenarbeit!
Der Vorteil solcher in Translation Memories integrierten Datenbanken für den Kunden ist auf jeden Fall, dass er genau weiß, wenn er »Hartmann Fachübersetzungen« mit seiner Übersetzung beauftragt, dass seine Übersetzung mit einem Translation Memory erledigt wird, die über einen integrierte Fachwortliste verfügt, sodass er die Sicherheit hat, es werden nicht nur stets die korrekten Fachbegriffe verwendet, sondern ggf. auch die in seiner Firma üblichen und gebräuchlichen Fachbegriffe, und das ist ihm wichtig. Daher sollten auch Sie sich bei der Vergabe von Übersetzungsaufträgen Ihres Handbuchs oder Ihrer Betriebsanleitung für »Hartmann Fachübersetzungen« entscheiden!

Nein. Es können auch immer wieder kehrende Wortgruppen oder sogar ganze Sätze in Datenbanken von Translation Memories aufgenommen werden. Dies macht vor allem bei Standards, Normen und Richtlinien Sinn. Nehmen wir als Beispiel mal die Fachgrundnorm aus dem Bereich der elektromagnetischen Störfestigkeit EN IEC 6100-6-1-2019 „Störfestigkeit für Wohnbereich, Geschäfts- und Gewerbebereiche sowie Kleinbetriebe“. Jeder technische Übersetzer wird zwar in der Lage sein, den Wortlaut dieser Norm „irgendwie“ ins Englische zu übersetzen. Kann gut gehen - muss aber nicht. In der Übersetzungswissenschaft gibt es den Begriff der ‚autorisierten Übersetzung‘, d.h. zum Beispiel Standards oder offizielle Normen und Richtlinien dürfen nicht „irgendwie“ übersetzt werden, sondern nur so, wie diese bereits in zahlreichen Veröffentlichungen im Internet oder einschlägiger Fachliteratur o.dgl. übersetzt worden sind. Insofern sollte der technische Übersetzer also diese Quellen durchsuchen, eine zuverlässige Quelle heraussuchen, die eine plausible Übersetzung anbietet und diese verwenden. In diesem Fall sollte der technische Übersetzer von Fachtexten, die Normen und Standards enthalten, die übersetzt werden müssen, wie folgt vorgehen: Er ruft (idealerweise) https://www.google.co.uk/ auf; dort findet er vorzugsweise Entsprechungen aus dem originalenglischsprachigen Raum. Dann gibt er die alphanumerische Bezeichnung des Standards ein - in diesem Fall EN IEC 6000-6-1-2019. Das reicht aber in der Regel noch nicht aus, um genügend Übersetzungsäquivalente zu finden. Unsere Praxis hat gezeigt, dass es sich empfiehlt, das, was man im Englischen als Übersetzung vermutet und „ungefähr hinkommen könnte“, bei Google einzugeben und zu prüfen, welche Übersetzungsäquivalente vorgeschlagen werden. Hier würde sich z.B. anbieten, neben der Bezeichnung der Norm EN IEC 6000 usw. „electromagnetic immunity for the residential area“ einzugeben, und wir finden dann gleich unter https://webstore.iec.ch/publication/25631 die korrekte Bezeichnung für die gesuchte deutschsprachige Norm: „Electromagnetic compatibility (EMC) - Part 6-1: Generic standards - Immunity standard for residential, commercial and light-industrial environments“. Nach einer gründlichen Überprüfung auf Plausibilität und Häufigkeit (bei mehreren Übersetzungsvarianten sollte man sich immer für die entscheiden, die bei der Google-Suche am häufigsten vorkommt) wird dann die gesamte Norm - in diesem Fall als Sprachpaar Deutsch - Englisch - in das Fachwortglossar (dieses heißt bei uns „Standards_und_Normen“) aufgenommen, und wenn wieder eine Übersetzung kommt, in der genau diese Norm vorkommt, erscheint diese markiert (z.B. rot), wird als Übersetzungsäquivalent angeboten, und der Übersetzer kann dies so übernehmen und braucht nicht nochmals nach der autorisierten Übersetzung dieser Norm zu suchen.
